

Spectral Sheaves
This post is based on my thesis proposal presentation.
Introduction
My research plan stems from a very simple observation: whenever you have a coboundary operator acting on a finite-dimensional vector space, you can define a Laplacian. The traditional manifestation of this fact is the graph Laplacian, the source of so much joy in spectral graph theory. There we consider the coboundary operator and form the Laplacian . The spectrum of can tell you a lot about the graph.
But there’s another simple situation where we have a coboundary operator: a sheaf on a graph. A sheaf on a graph is an assignment of a vector space to each vertex , a vector space to each edge , and a map for each incident edge-vertex pair . The vector spaces and are called stalks over and , and the map is called a restriction map. We get two vector spaces of cochains, , and . Assigning an orientation to the edges of gives us an incidence number depending on whether the edge is oriented toward or away from the vertex. This lets us define a coboundary operator by .
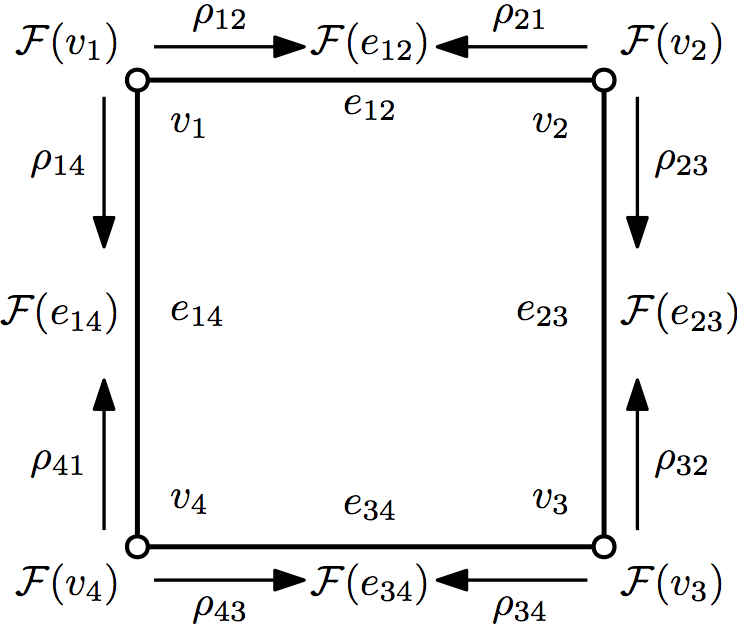
How should we think about a sheaf on a graph? We can assign local data to each vertex. The restriction maps tell us when an assignment of data is globally consistent. So a sheaf mediates the passage from collections of local information to a global picture. We call an assignment of data to each that is consistent over the edges a global section. That is, is a global section if for all edges . A moment of consideration will show that is a global section precisely when .
We now have a coboundary operator and want to construct its associated Laplacian. To do this, we need one more piece of information: an inner product on each stalk and allows us to identify these spaces with their duals and take the adjoint of . Then we define as before. A standard result from linear algebra says that , and further, , so is positive semidefinite.
I’m not the first one to make these observations. Joel Friedman proved the Hanna Neumann conjecture using something he called sheaves on graphs. (Under our definitions, these would be cosheaves on graphs—-the maps go the opposite direction.) As an aside in the introduction of this paper, he suggested defining Laplacian and adjacency matrices for sheaves and studying their spectral properties. Others have worked with special cases of the sheaf Laplacian, most notably the work by Singer and various others on the graph connection Laplacian, which is the Laplacian of a sheaf all of whose restriction maps are in .
Results
Eigenvalue interlacing
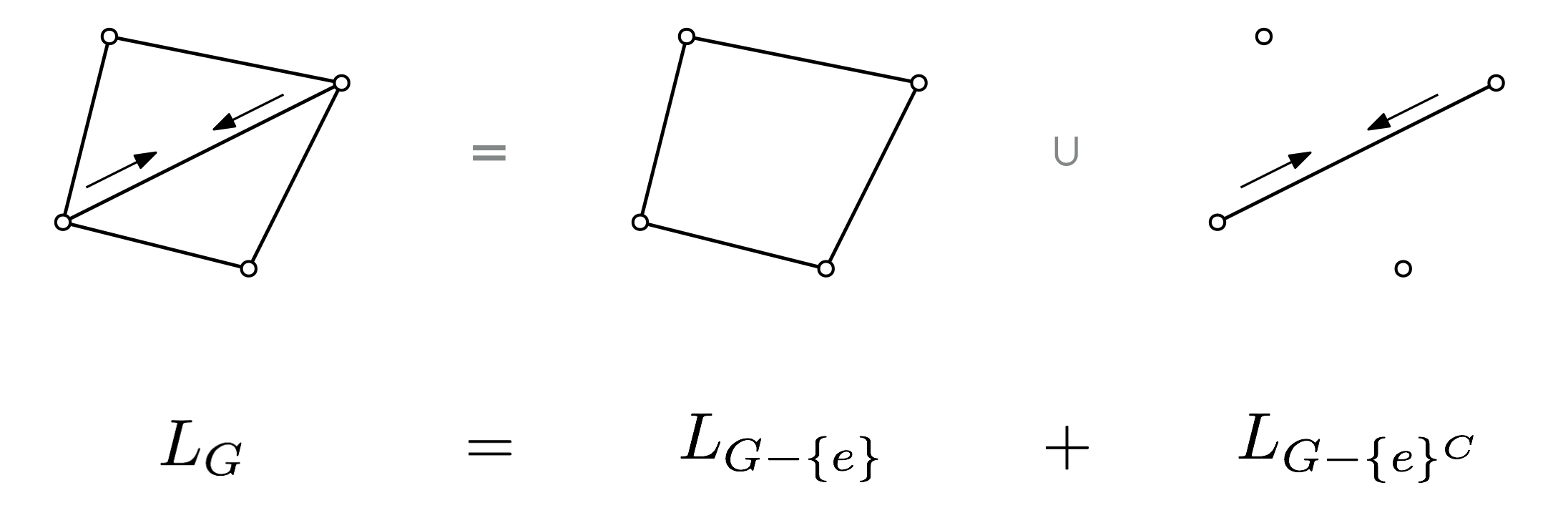
One of the first questions you might ask about graph spectra is what happens to the spectrum of a graph when you remove an edge. It’s natural to ask the same question about a sheaf on a graph. The way to get the required information is to look at the Laplacian of the larger graph as the sum of two Laplacians: one corresponding to the smaller graph, and one corresponding to the removed edge. To understand how the spectra are related, we define a notion of interlacing:
Let , be matrices with real spectra, and let be the eigenvalues of and be the eigenvalues of . We say the eigenvalues of are -interlaced with the eigenvalues of if for all , . (We let for and for .)
We now show that the eigenvalues of sheaf Laplacians are interlaced after deleting a subgraph. Let be a sheaf on a graph , and let be a collection of edges of , and denote to be with the edges in removed. Let be the sheaf Laplacian of and the sheaf Laplacian of . Define further the sheaf to be the sheaf with the same vertex stalks as but with all edge stalks over edges not in set to zero. Then we have the following:
Proposition
The eigenvalues of are -interlaced with the eigenvalues of , where .
Proof. Notice that , where is the Laplacian of . By the Courant-Fischer theorem, we have
and
Pullbacks and covering maps
If you have a morphism of graphs, a sheaf
on can be turned into a sheaf on by
letting ,
, and
be equal to
. This is known as the pullback sheaf. There is a
natural map whose
definition you can probably figure out faster than I can type it. This
map is nice in that ; in particular this
means that every section of lifts to a section of
. Anyone familiar with cohomology should not be
surprised by this fact: it is essentially the fact that cohomology is a
contravariant functor. On the other hand, does not commute with
in general. But if is a covering map, it does!
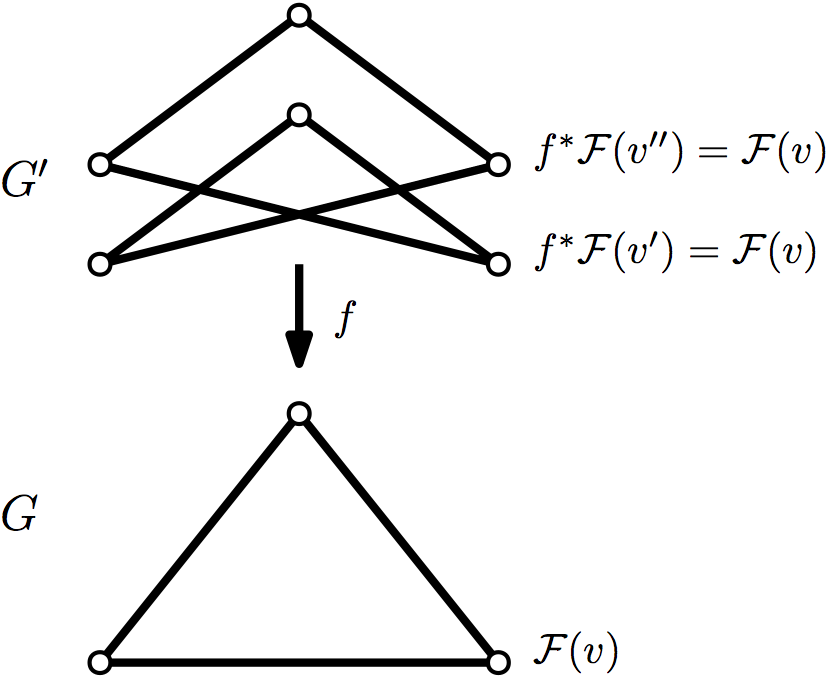
Lemma
Suppose is a covering map of graphs; that is, for any vertex , is an isomorphism of graphs when restricted onto the neighborhood of . Then .
Proof. For and , we have
The first equality is by definition of the adjoint, the second the definition of the coboundary map, the third the definition of , and the fourth equality holds because is a covering map. The fifth equality comes from computing the adjoint of , the sixth from the definition of , and the last again from the definition of adjoints.
The key point is that every vertex in maps down to a vertex whose neighborhood looks exactly the same.
The fact that commutes with means we can say a lot about the spectrum of . In particular, we know that if , then , so is an eigenvector of with eigenvalue . So the spectrum of is contained in the spectrum of . So we have
Theorem
If is a covering map of graphs, with a sheaf on , then .
Harmonic functions
Harmonic functions are perhaps most familiar from analysis, where they share many nice properties with holomorphic functions. One of these is an averaging property: the value of a harmonic function at a point is equal to the average value of the function on a sphere centered at the point. Another is the maximum principle: a function which is harmonic on some compact set attains its maximum on the boundary of the set. We can define an analogous condition for functions on graphs: a function is harmonic at a vertex if . Equivalently, the value of at is equal to the (weighted) average of the value of at neighbors of . This definition generalizes immediately to sheaves, and we note that the functions which are everywhere harmonic are precisely the global sections of the sheaf.
Harmonic functions on graphs also satisfy a maximum principle: a function on a graph which is harmonic away from some boundary set , where every vertex in is connected to the rest of the graph, attains its maximum value on . There is a further extension to sheaves whose restriction maps are all in the orthogonal group : a 0-cochain which is harmonic away from a set attains its maximum pointwise norm on . To be precise, we have:
Proposition
Let be an a weighted sheaf on a graph with all restriction maps in . Suppose , and that is harmonic on a subset of vertices . Further suppose that the subgraph induced by is connected, and that every vertex of is connected to . Then if attains its maximum norm on , its vertexwise norm is constant.
Proof. Let and suppose for all . Then because is harmonic at ,
Therefore, equality holds throughout, so for any . But by hypothesis, every vertex in is connected via a path lying in to , so we can repeat this argument to show that is constant for all . But now this argument shows that is also constant for every .
Sparsification
Graphs can be complicated; a graph on vertices can have edges. Often, it would be nice if we could replace a graph that has many edges with one that has relatively fewer. Of course, we want the smaller graph to share important properties with the original graph. One way to measure this similarity is using the Laplacian spectrum of the graph. Given two symmetric matrices , , we say that if is positive semidefinite. This imposes a relationship between both the eigenvalues and eigenvectors of and .
Spielman and Teng give a sparsification result for weighted graphs:
Theorem (Spielman and Teng 2011)
Let be a weighted graph with vertices. Given there exists a weighted graph on the same vertex set with edges such that .
The proof involves randomly sampling edges with probability proportional to their effective resistance. A good exposition is found in Spielman’s course notes. Their proof generalizes immediately to sheaves on graphs:
Theorem (Hansen 2017)
Let be a weighted sheaf on , a graph with vertices. Given there exists a subgraph with edges and a sheaf on such that .
Effective resistance is replaced by a similar notion involving the pseudoinverse of the Laplacian and submatrices of the coboundary. Everything else proceeds exactly as in the proof for graphs.
But this theorem actually extends to simplicial complexes as well:
Theorem (Osting, Palande, Wang 2017)
Let be a weighted -dimensional simplicial complex with -simplices. Given there exists a weighted complex with the same -skeleton and -simplices such that .
Here is the ‘up’- or coboundary-Laplacian defined on -cochains, i.e. .
There doesn’t appear to be anything that stops the following conjecture from holding, although I have not yet written out the proof:
Conjecture
Let be a sheaf on , a -dimensional simplicial complex with -simplices. Given there exists a subcomplex with the same -skeleton and -simplices, along with a sheaf on such that .
This last conjecture is equivalent to the following:
Conjecture
Let be an matrix, with -block row sparse, that is, each block row of has at most nonzero blocks. Then there exists a matrix with nonzero blocks such that .
Note that here the constants in the must depend on , since any is -row sparse for .
There are further results in sparsification for graphs, with increasing levels of numerical and theoretical sophistication, giving even smaller approximations to graphs. In particular, the following result shows that we can in fact get linear-size spectral sparsifiers:
Theorem (Batson, Spielman, Srivastava 2012)
Let be a weighted graph on vertices. Given , there exists a graph on the same vertex set with at most edges such that .
The proof of this theorem gives a deterministic algorithm, and relies on iteratively removing edges from the graph and applying the rank-one update formula. There are analogous formulas for block matrices, which suggests it may be possible to extend this result to sheaves on graphs.
Objectives
My goals with this project are both pure and applied. One goal is straightforward and easily explained: generalize as much of spectral graph theory as possible to sheaves on graphs. This involves finding the right way to lift various graph theory concepts to the world of sheaves. Then I have a couple of broader programs that relate to applications. I want to build a language and toolbox for modeling systems using sheaves, and I want to apply sheaves to data analysis problems.
Spectral Sheaf Theory
Generalizing results about graphs to results about sheaves relies on some analogies:
| Graphs | Sheaves |
|---|---|
| vertex/edge | element of a stalk over a vertex/edge |
| subset of vertices | partial section/cochain |
| number of vertices | norm of a section/cochain |
| incident edges | coboundary of a cochain |
Cheeger inequality. The Cheeger inequality for graphs gives a nice relationship between the graph’s spectrum and its connectivity properties. If is the second-largest eigenvalue of the normalized Laplacian of , we know that is connected if and only if . In some sense, we want to say that the larger is, the better connected is. We make this precise by defining the Cheeger constant of a graph to be
Here is the (weighted) count of edges between and its complement, and is the number of edges incident to vertices in . Intuitively, the Cheeger constant is the solution to an optimization problem trying to find the smallest cut that divides the graph into two subgraphs of roughly equal size. The Cheeger inequality then asserts that .
There is a version of the Cheeger inequality, due to Bandeira, Singer, and Spielman, that applies to -vector bundles on graphs. Here the Cheeger constant is replaced with a frustration constant minimizing over cochains which are locally either zero or norm 1:
The generic -vector bundle over a graph has no global sections, so the Cheeger inequality here corresponds to the smallest eigenvalue : .
This offers one way to try to generalize the Cheeger inequality to sheaves. However, the proof they give does not generalize to sheaves with non-unitary restriction maps, since a key inequality relies on the fact that restriction maps are norm-preserving.
Other ways to generalize the Cheeger inequality to sheaves might include finding a minimal modification of the restriction maps of the sheaf so that it supports a global section and relating the amount of change necessary to the spectrum of the sheaf.
Identifying Laplacians. It’s easy to tell if an arbitrary symmetric matrix is the Laplacian of a weighted graph: check whether its diagonal is nonnegative and its row sums are zero. The problem is considerably more subtle if we want to identify sheaf Laplacians. Consider the following examples with one-dimensional stalks and two vertices:

This matrix doesn’t have zero row-sums, but it is still weakly diagonally dominant.

This matrix is not even weakly diagonally dominant. It is, however ‘globally’ diagonally dominant: the sum of diagonal entries is strictly greater than the sum of absolute values of off-diagonal entries.
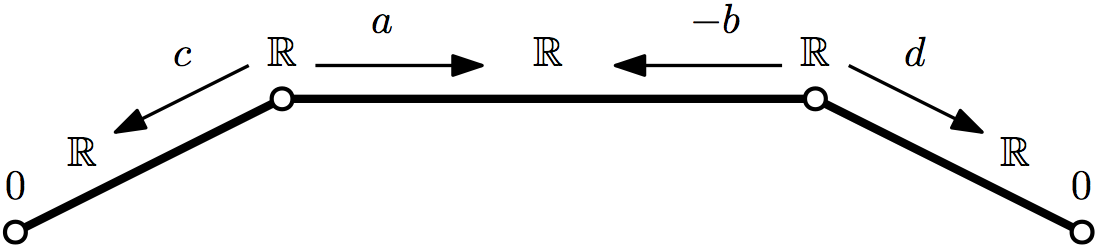
In general, a sheaf Laplacian looks like this. We include the degenerate edges with zero stalk over one vertex for completeness and convenience. In fact, every symmetric positive semidefinite matrix can be written in this form. But this does not hold for larger matrices. There is, however, a necessary condition based on the case: To be the Laplacian of a sheaf with one-dimensional stalks, a matrix must be totally globally diagonally dominant. That is, for every principal submatrix of , must be globally diagonally dominant as defined above. However, this condition is not sufficient: the matrix
is not a sheaf Laplacian, but it is totally globally diagonally dominant.
When stalks are one dimensional, the question of whether is a sheaf Laplacian is equivalent to whether there exist vectors with at most two nonzero entries such that . This question of sparse decomposability seems relevant to an interesting statistics problem: Given a vector-valued random variable , when is it possible for to have been generated by a sparse collection of independent random variables? That is, is the sum of independent random variables, each affecting at most two coordinates of ? A necessary condition is that the covariance have a sparse decomposition in the sense just mentioned. This seems similar to a sparse version of principal component analysis, but current formulations of sparse PCA actually end up explaining too much variance: subtracting off all the sparse principal components leaves you with a matrix which is no longer positive semidefinite.
Applications to Systems
Dynamical Systems on Sheaves. Wherever we have a Laplacian, we want to construct heat and wave equations. These are the differential equations and . The long-term behavior of the heat equation is determined by the spectrum of . In particular, the trajectory converges to the global section nearest to the initial condition. Distributed systems often use the heat equation for the graph Laplacian to achieve consensus on a value; the sheaf heat equation generalizes this concept.
The wave equation might be interesting for studying things like coupled systems of oscillators. It’s also worth noting that we can construct a Laplacian that acts on the edge stalks instead of the vertex stalks; this might be useful for other, more topological things.
The Moduli Space of Sheaves. If sheaves represent systems, then to work in the realm of possible systems, we need to study the space of sheaves. In particular, we want to ask questions like:
-
How does the spectrum change as we change the sheaf?
-
How to find the nearest sheaf with global sections?
-
How to get a simpler sheaf that preserves important properties?
-
What is a (uniformly chosen) random sheaf?
We can get coarse answers to some of these questions with spectral methods. For instance, sparsification by effective resistance works to simplify a sheaf while preserving its spectrum. Conversely, removing edges of high effective resistance pushes the sheaf closer to having global sections.
Applications to Data
Point Clouds. Sheaves have a long history of use to describe geometry. You can reasonably define a geometric space as a topological space together with a sheaf of functions on the space. So if we want to describe data geometrically, one natural approach (if you think like a pure mathematician, at least) is to try to put a sheaf on the data. This is sort of what Singer and Wu did when in their paper about vector diffusion maps and the graph connection Laplacian. They take a point cloud (assumed to be sampled from a manifold) and use local PCA to approximate the tangent space at each point, and solve the orthogonal Procrustes problem to approximate local parallel transport between tangent spaces. This fits together in an -vector bundle on the nearest-neighbor graph of the point cloud, and its associated Laplacian converges to the connection Laplacian of the manifold as the sampling density increases.
Of course, manifolds are a very special case of geometric space; in general, we don’t have a reason to assume the local dimension of our data is constant. My goal here is to investigate geometrically motivated methods that work for spaces of non-constant dimension. A simple extension of the Singer-Wu model is to simply allow the local dimension for PCA to vary, and solve a generalized orthogonal Procrustes problem to get ‘parallel transport’ maps that are rotations composed with orthogonal projections. The structural math here works out exactly as in the constant-dimension case, but it’s more difficult to interpret. What does it mean for a vector to be sent to zero under parallel transport? What continuous construction, if any, would this converge to under increasing sampling density?
A more sophisticated, better theoretically motivated construction might return to the idea of a sheaf of functions. Instead of locally approximating data by a hyperplane, as in PCA, we can get a local approximation by low-degree polynomial level sets, and construct a local space of polynomial functions for each point, hoping to patch them together via restriction maps on edges. You could look at this like a scheme, but with a finer topology than the Zariski topology.
Synchronization. The study of synchronization problems was (is being?) pioneered by Afonso Bandeira and Amit Singer. The idea behind synchronization as an approach to data analysis is that we can estimate some global information from information about local relationships. This is kind of vague. The standard example is the -synchronization problem. For concreteness, suppose we have a collection of 2D images of the same scene, but rotated differently. However, we know the relative orientations for various pairs of images. The goal for synchronization is to find a global orientation that agrees with all these pairwise rotations. A nice introduction to various sorts of synchronization problems from a very algorithmic perspective can be found in Bandeira’s notes from an MIT course in the mathematics of data science.
“Get global information from local information” is exactly the slogan for sheaf theory, so it’s natural that synchronization problems can be formulated in terms of sheaves on graphs. Every synchronization-type problem I have seen can be stated as “find an (approximate) global section for a given sheaf.” This is more general than the framework proposed by Gao, Brodski, and Mukherjee using vector bundles. The sheaf formalism, combined with spectral methods, should lead to better insights into what is possible in the world of synchronization.
There are actually a number of synchronization-like problems leveraging sheaf structure to get new information about data:
-
(Synchronization) Given a sheaf, find an approximate global section or set of sections.
-
(Sheaf approximation) Given maps associated to incidence relations of a cell complex, find the nearest sheaf, or find the nearest sheaf admitting global sections.
-
(Clustering) Given a sheaf on a graph, find groups of connected vertices which support local sections.
-
(Learning) Given cochains and frustrations (and a graph/cell complex), determine sheaf restriction maps.
Conclusion
Sheaves are a natural language for talking about many interesting problems, some of which I have outlined here. My goal is to build tools that make thinking with sheaves easier and more powerful. Spectral graph theory has powerful concepts which can be adapted to sheaves, and the more we know about the spectral theory of sheaves, the better equipped we will be to approach new problems. Conversely, it doesn’t seem unreasonable that sheaves might have something to offer back to spectral graph theory. I now have a lot of work to do!